JLupin Next Server – pierwsze kroki, pierwsze usługi
W poprzednim wpisie było trochę dupereli o mikroserwisach. Dlaczego są nie do końca OK oraz jak JLupin może pomóc nam ogarnąć tę kuwetę. Dziś będziemy bawić się już w programowanie i na przykładach zademonstruję co i jak.
Co piszemy?
Jak już 11 lat bloga prowadzę, to zawsze przewijał się na nim temat bankowości. Banki duże, banki małe, systemy rozliczeniowe, windykacyjne, transakcyjne, raportowanie i cała masa innych niegodziwych elementów tego szatańskiego tworu zwanego systemem bankowym. Dlatego też bez zaskoczenia. Napiszemy bank. Dokładnie napiszemy sobie fragment związany z kontami, klientami i jakieś proste raportowanie. Docelowo będziemy mieli tu kilka aspektów, które ładnie będzie można przenieść na poszczególne usługi:
- Klienci i konta – informacje o klientach i ich kontach, czyli takie typowe CRUD-owe usługi.
- Operacje finansowe – tu będzie się działo mięsko związane z przelewaniem kasy.
- Raportowanie – zazwyczaj w takim miejscu jest jakiś system raportowo-analityczny, my zrobimy sobie wydmuszkę.
- Parametryzacja – pewne elementy banku muszą być pobierane z parametrów biznesowych.
- API Gateway – końcówka dla klientów.
By jeszcze sobie utrudnić życie, a jednocześnie móc zademonstrować kilka elementów JLNS, wprowadzimy funkcjonalność „partnerów”, czyli coś, co na co dzień znamy jako kredyty sprzedawane w sklepach z AGD, albo karty kredytowe marketów.
Oczywiście będzie dużo uproszczeń (albo i nie), ale na początek zajmiemy się czymś zupełnie trywialnym Przygotujemy projekt w IntelliJ. Jest to o tyle proste, że JLNS udostępnia wtyczkę do IDE. Obrazkowo będzie.
Projekt Bankster
Na początku oczywiście menu „Create new Project” i następnie wybieramy projekt JLupinowy
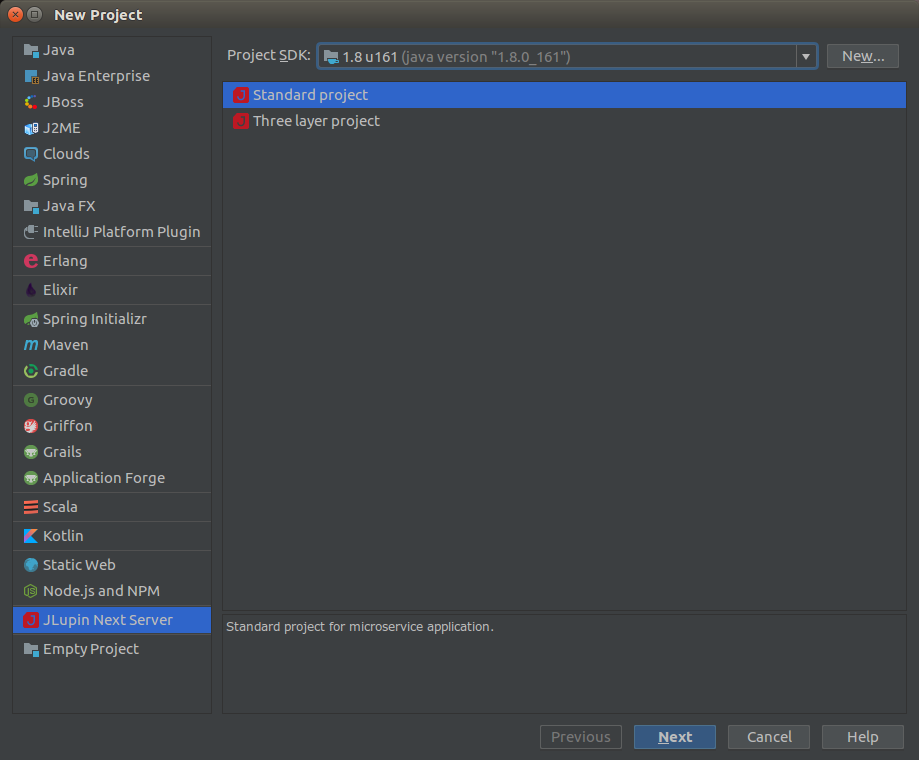
Kolejnym krokiem jest określenie wersji grupy mavenowej oraz miejsca, w którym zapisaliśmy zipa zawierającego serwer. Osobiście uważam, że osadzanie serwera w ramach projektu jest po prostu wygodne. Czasami trzeba coś pogrzebać w konfiguracji czy rzucić okiem na logi.
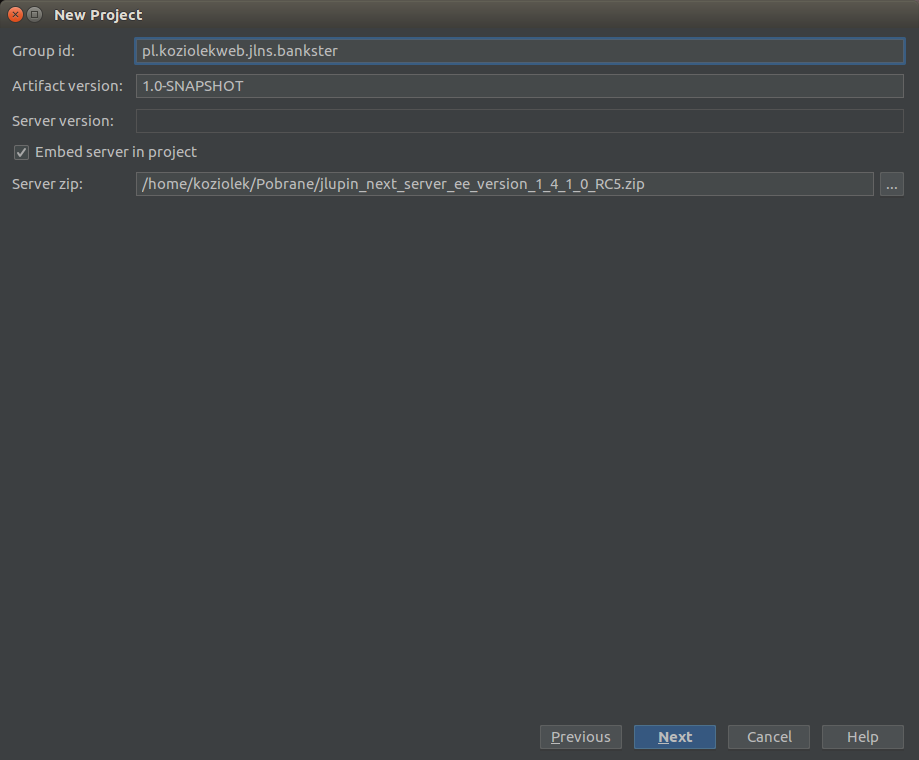
Następnie stworzymy sobie projekt, który będzie ogarniał API Gateway:
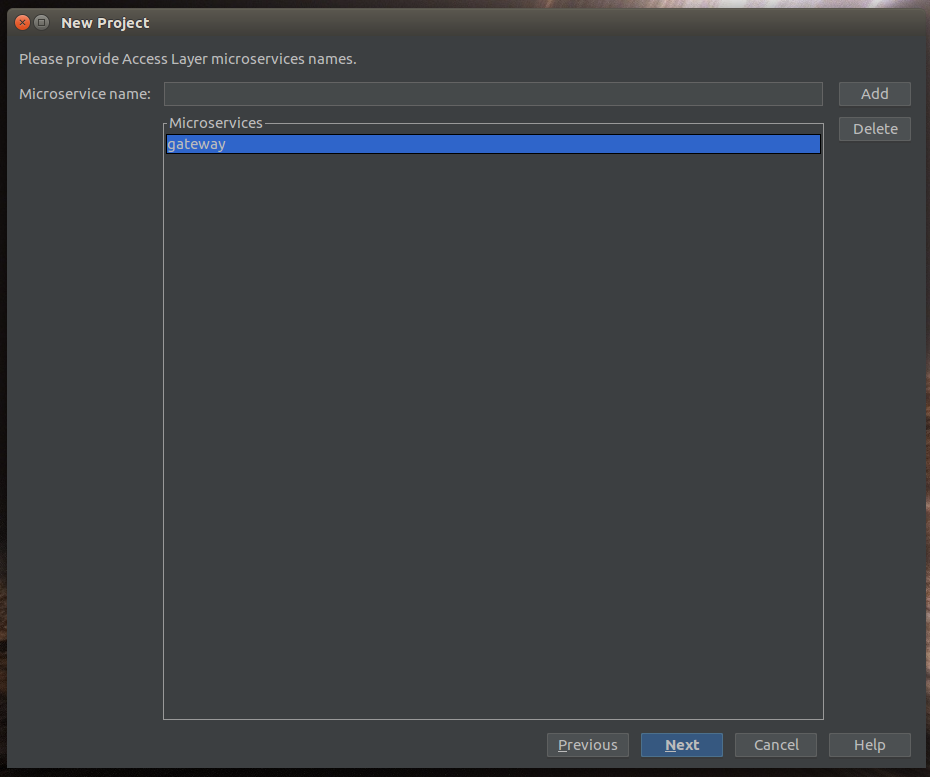
Do tego dodajmy projekty dla klienta i rachunków oraz ich „tło” do składowania danych:
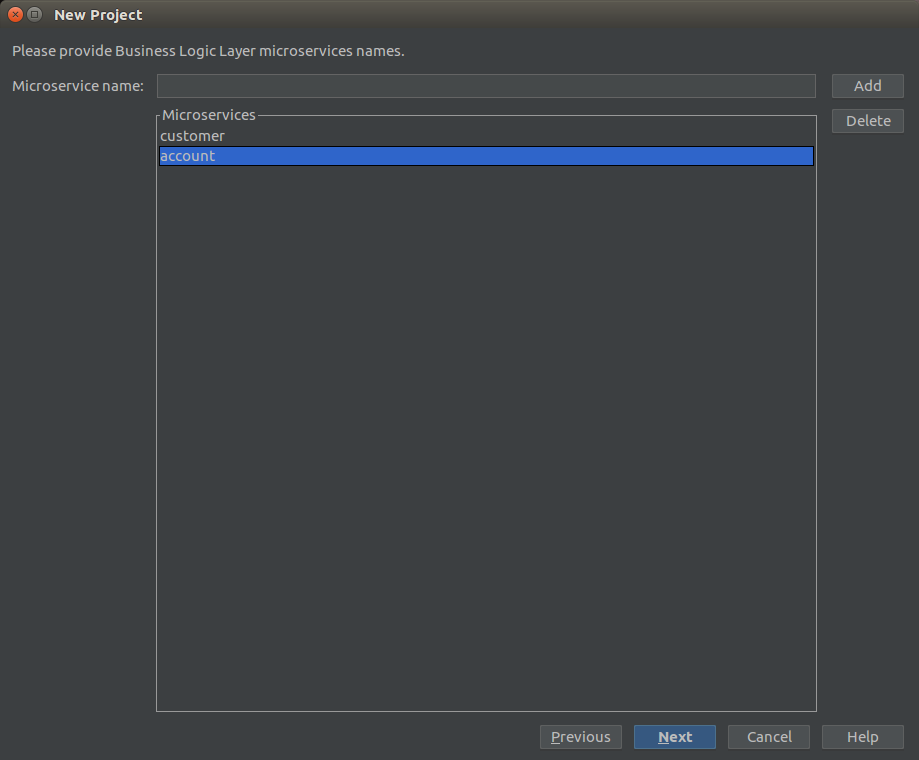
Na koniec nadajemy całości nazwę bankster i gotowe:
Na obecnym etapie otworzy się okno IDE, w którym mamy podgląd do naszej architektury:
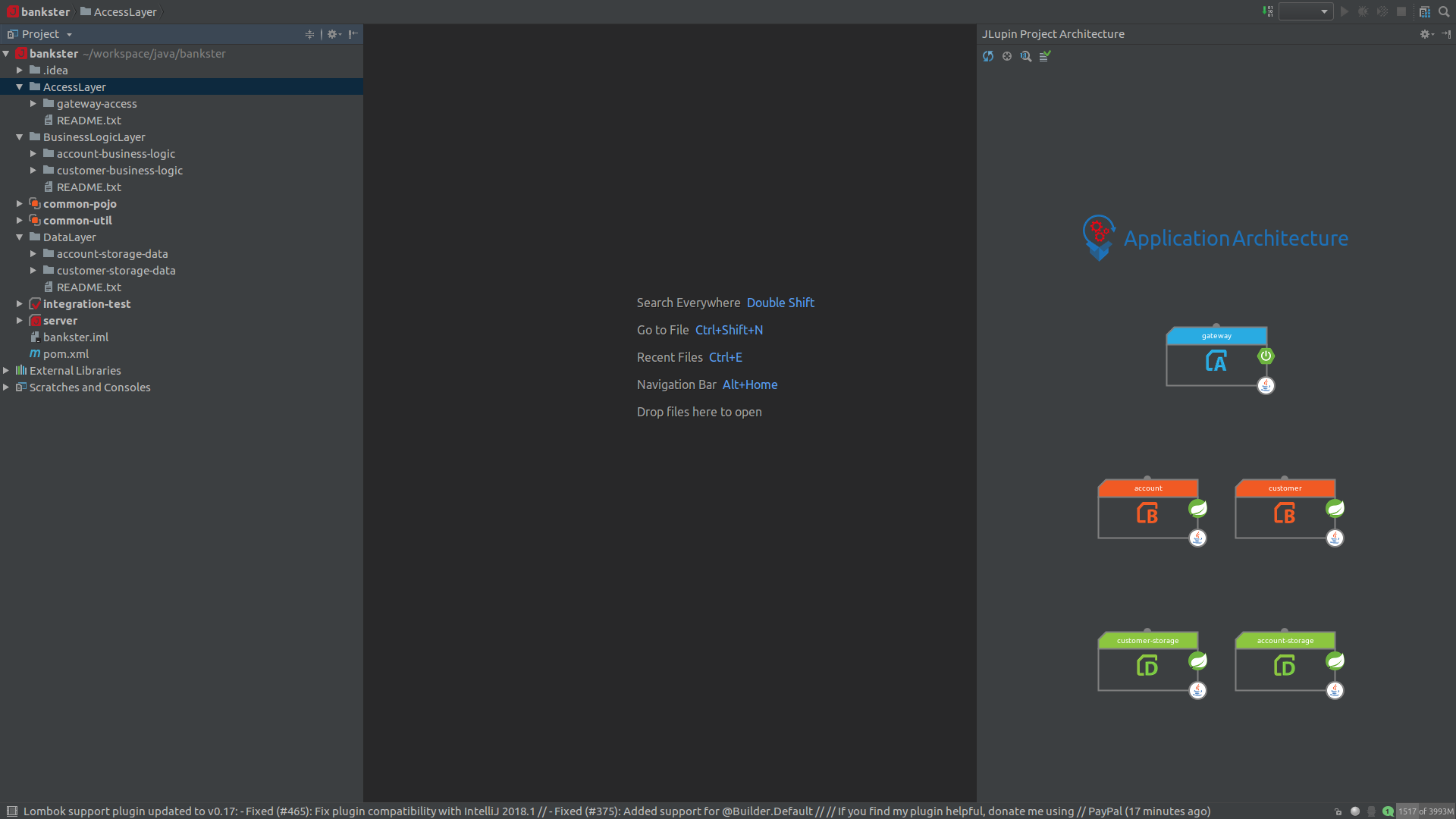
Podgląd co prawda nie jest najlepszy, bo nie pozwala nam na tworzenie zależności za pomocą drag’n’drop, ale lepsze to niż nic. Szczególnie że przy
większych projektach i tak szybciej będzie dodać zależność w pom.xml niż kombinować z myszką.
Struktura projektu
Przyjrzyjmy się teraz strukturze projektu. Pierwszą rzeczą, która rzuca się w oczy, jest organizacja modułów. Poszczególne projekty są modułami
głównego projektu. I to jest nie do końca OK. Taki układ wymusza na nas pracę z projektem jak z monolitem. W dodatku trudno będzie zarządzać takim
projektem, tak by poszczególne usługi miały swoje repozytoria. Moim zdaniem jest to bardzo duży błąd ze strony twórców. Z drugiej strony pozwala, to
na zarządzanie całością z jednego miejsca. Trochę innym podejściem jest stworzenie projektu typu bom, w którym upakujemy konfigurację zależności.
Przyjmijmy jednak, że ta domyślna konfiguracja ma jakiś głębszy sens. Przyjrzyjmy się, jak wyglądają poszczególne projekty.
Zacznijmy od gatewaya. Projekt ten umieszczony jest w katalogu ./AccessLayer/gateway-access/. Znajdziemy tam dwa katalogi. Pierwszy
to additional-files, w który znajdują się dwa pliki:
log4j2.xml– zawiera konfigurację log4j2, która zostanie wykorzystana przez techniczne elementy usługi. Jest to też domyślny log usługi.- servlet_configuration.yml – tu znajdziemy konfigurację usługi, która obejmuje kanały komunikacyjne, pamięć, bufory, ale też na przykład zasady rotowania logów.
Pozostałe podprojekty mają taką samą strukturę. Przy czym projekty z warstwą biznesową znajdują się w
katalogu ./BusinessLogicLaywer/{account,customer}-businesslogic/, a projekty związane z dostępem do danych w
katalogu ./BusinessLogicLaywer/{account,customer}-storage-data/. Sama struktura poszczególnych projektów jest następująca:
./additional-files/– to samo co wyżej, czyli konfiguracja, ale zamiastservlet\_configuration.yml, mamyconfiguration.yml../interfaces/– w tym projekcie definiujemy interfejsy naszej usługi. Co ważne inne usługi korzystające z naszego serwisu będą zależne od tego właśnie projektu../implementation/– implementacja naszych usług. Tym się nie musimy z nikim dzielić.
Poza wyżej wymienionymi elementami mamy jeszcze:
common-pojo– w tym projekcie leżą sobie klasy, które reprezentują pewne podstawowe struktury danych w naszym systemie. W praktyce to kubeł na różne VO.common-utils– skrzynka na narzędzia. Tu umieść klasęStringUtils. Na pewno będziesz jej potrzebować.integration-test– w tym miejscu leżą testy integracyjne, które można odpalić w procesie CI/CD.
Rodzaje mikroserwisówserwisów
Taka organizacja poszczególnych projektów jest wynikiem wyróżnienia dwóch rodzajów mikroserwisów.
Mikroserwisy servletowe
Pod tą nazwą kryją się mikoserwisy, które są aplikacjami webowymi. Co do zasady jest to spring boot. Mikroserwisy te wystawiają API na potrzeby naszych klientów. Na tym poziomie mamy dostęp do naszej aplikacji za pośrednictwem HTTP(S) i możemy pisać aplikacje zgodne ze specyfikacją servletową. Z drugiej strony usługi te są pozbawione wbudowanych kolejek, które pozwalają na tworzenie reaktywnych rozwiązań. Nie jest to nic dziwnego, bo tu nie potrzebujemy tego typu magii.
Mikroserwisy natywne
Czyli aplikacje (jary), które zawierają logikę biznesową, zarządzają danymi, komunikują się z innymi, zewnętrznymi usługami. Tych usług nie wystawiamy na zewnątrz bezpośrednio. Jednocześnie stanowią one największą część naszej aplikacji.
Podsumowanie
Praca z JLNS w zakresie tworzenia projektów jest bardzo prosta. Z drugiej strony niektóre pomysły twórców uważam za swoistą pomyłkę np. super-projekt mavenowy. Warto też zwrócić uwagę na jeszcze jeden aspekt. JLNS bardzo intensywnie wykorzystuje Spring Framework, ale jeżeli chcemy pisać bez wsparcia ze strony Springa, to nadal możemy to robić. W kolejnej części zaczniemy wiązać usługi między sobą i zaimplementujemy jakiś prosty przypadek użycia.